# readrパッケージのインストール・読み込み
install.packages("readr")
library(readr)(2) Rの基本操作②:データフレーム
1 はじめに
前回(1) Rの基本操作①:超基本操作・パッケージでは、R Studioを用いた基本的な演算・代入操作などに加えて、Rで必要不可欠なパッケージの利用方法を解説した。
本章では、前回同様にRに関する基本操作を説明するが、焦点はデータフレームに集中する。
2 データフレームとは?
データフレームはデータ分析において最もよく用いられるデータ構造であり、私たちが一般的に考える以下の様な表のことを表す。
| 都道府県 | 人口 | 県庁所在地 | 面積\((km^2)\) | 県内総生産(100万円) |
|---|---|---|---|---|
| 北海道 | 5043000 | 札幌市 | 83457 | 20889250 |
| 青森県 | 1165000 | 青森市 | 9645 | 4439055 |
| 岩手県 | 1145000 | 盛岡市 | 15279 | 4797050 |
| 宮城県 | 2248000 | 仙台市 | 6862 | 9614668 |
| 秋田県 | 897000 | 秋田市 | 11636 | 3629335 |
| 山形県 | 1011000 | 山形市 | 6652 | 4340427 |
| 福島県 | 1743000 | 福島市 | 13783 | 7864963 |
基本的に縦軸(行)が1つ1つの観測(北海道, 青森県, etc.)を表し、横軸(列)が変数(人口, 面積, etc.)を表す構造になっている。
皆さんが卒業研究などで分析を行なう際、ほとんどの学生は政府統計(E-Stat)や世界銀行データベースといった公的サイトからデータフレーム(excelファイルやcsvファイル)をダウンロードし、それらをRに読み込んで分析を行なう。
3 データフレームの読み込み
ここではデータフレームをRに読み込む方法を紹介する。
3.1 データフレームの検索・保存
先ず大前提として、自身の研究テーマに沿ったデータフレームを探して、任意のファイルに保存することから始める。1
ノート研究テーマの選び方(ミクロデータ・マクロデータ)
卒業論文の研究テーマ探しは非常に難しい問題であり、学部4年の上半期にある程度決まる学生もいれば、卒論提出2ヶ月前ぐらいで決まる学生もいる。計量経済学などのデータ分析を用いて卒業論文を書く場合、注意すべきなのはデータが存在するかどうか?である。
計量経済学(特にミクロ計量経済学)では、1つ1つの家計・個人の収入や健康状態といったミクロデータを分析に用いることが多々ある。しかしながら、そのようなデータは重大な個人情報を含んでおり、学部生の卒業研究では扱うことが出来ないものも存在する。公的なWebサイトで一般公開されているものは、1つの国・地域ごとの生産額や人口といったマクロデータがほとんどであろう。
皆さんが卒業論文でデータ分析を用いる場合は、そのテーマを分析できるデータが存在するか?、存在した場合、そのデータは利用可能かどうか?を考慮に入れながら、テーマを絞っていくことをオススメする。
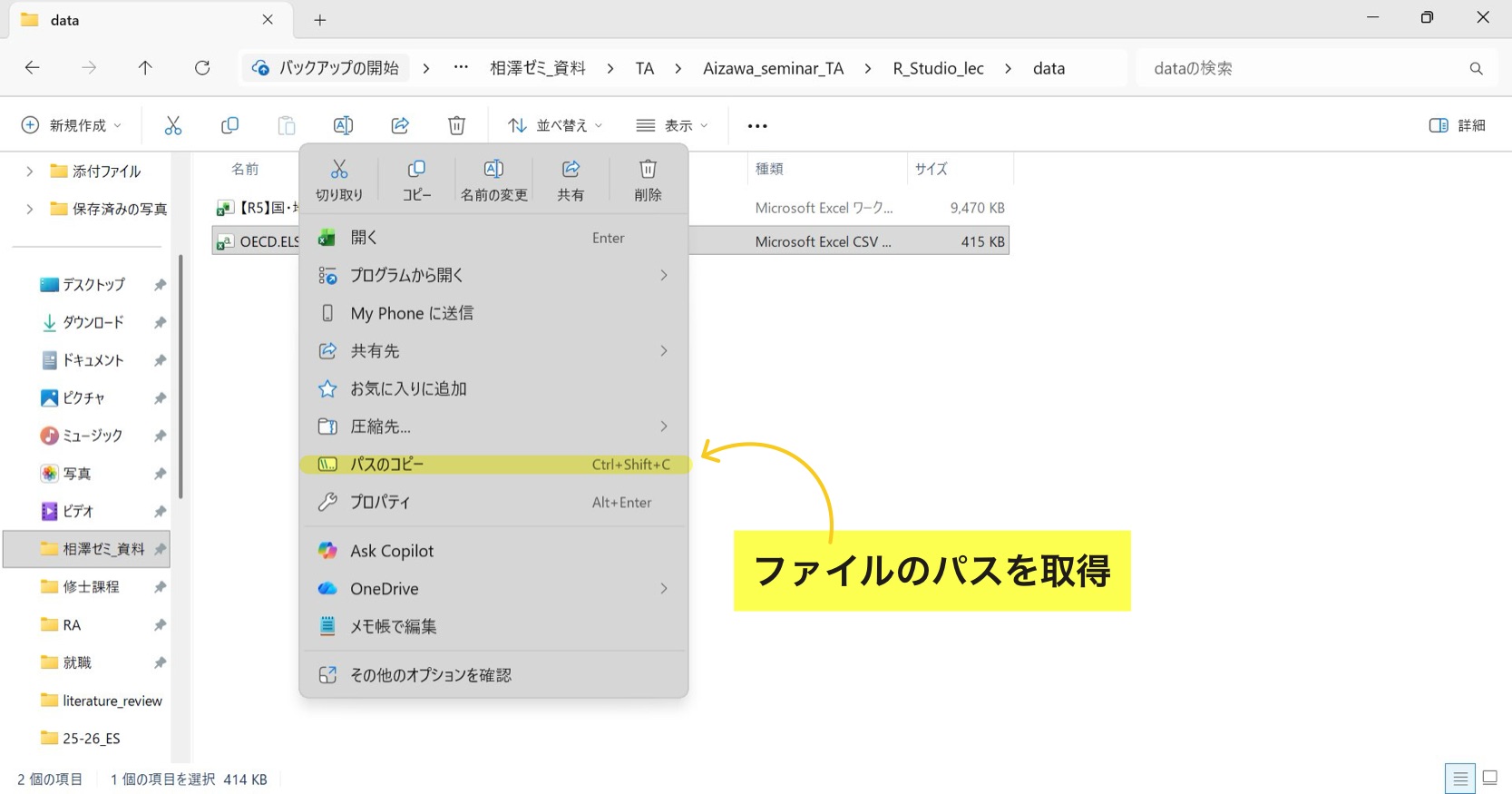
3.2 ファイルのパス取得
Webサイトでデータを何らかのファイルに保存し、Rで呼び出すとき、ファイルのパス と言うものが必要になる。これはそのデータがパソコン内のどこにあるかを示す住所のようなもので、"C:/Users/narita yoshiyuki/Desktop/相澤ゼミ_資料/TA/..."のような形になっている。
パスの取得方法は簡単で、ファイル→対象のデータを右クリック→パスのコピーで取得可能だ。
3.3 ファイルを読み込む関数
Rにデータフレームを読み込む場合、オブジェクト <- 関数(ファイルのパス, ファイルの文字コード指定)で、任意のオブジェクトにデータフレームを代入する必要がある。ここではその際に用いられる関数について、以下の2つのファイル形式における読み込み方法を紹介する。
- csvファイルの読み込み:
readr::read_csv() - excelファイル(拡張子が.xls または.xlsx)の読み込み:
readxl::read_excel()
3.3.1 csvファイルの読み込み:readr::read_csv()
csvファイルを読み込む際に用いる関数として、read_csv()が度々用いられる。{readr}パッケージに含まれる関数であり、他の読み込み関数に比べて高速で機能性が高い。2
ここでは読み込みの例といて、政府統計(e-Stat)上にある、「犯罪統計」からのデータを利用する(本データはここをクリックにあるcrime_statistics.csvから取得可能)。
# データフレームの読み込み(crimeというオブジェクトに代入する)
crime <- read_csv(
# ファイルのパス
"C:/Users/narita yoshiyuki/Desktop/相澤ゼミ_資料/TA/Aizawa_seminar_TA/R_Studio_lec/data/crime_statistics.csv",
# 文字コードの指定
locale = locale(encoding = "CP932"))Rows: 47 Columns: 7
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (2): 時間軸(年次), 管区警察局
dbl (1): 検挙率【%】
num (3): 認知件数【件】, 検挙件数【件】, 検挙人員【人】
lgl (1): /認知・検挙件数・検挙人員
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.# データフレームを軽く表示してみる
crime# A tibble: 47 × 7
`時間軸(年次)` 管区警察局 `/認知・検挙件数・検挙人員` `認知件数【件】`
<chr> <chr> <lgl> <dbl>
1 2016年 北海道 NA 32013
2 2016年 青森県 NA 5050
3 2016年 岩手県 NA 4223
4 2016年 宮城県 NA 16466
5 2016年 秋田県 NA 2947
6 2016年 山形県 NA 4896
7 2016年 福島県 NA 11575
8 2016年 東京都 NA 134619
9 2016年 茨城県 NA 26607
10 2016年 栃木県 NA 13253
# ℹ 37 more rows
# ℹ 3 more variables: `検挙件数【件】` <dbl>, `検挙率【%】` <dbl>,
# `検挙人員【人】` <dbl>上記の様にコードを書いて実行すると、画面右上(Environment)の部分にcrimeという代入されたデータフレームが表示されるはずだ。これでcsvファイルの読み込みは完了である。
ノート文字コードの指定
文字コードとは、パソコン上で文字を扱うために、文字に対して割り当てられた数値のことであり、様々な種類が存在する(UTF-8, Shift_JIS, CP932, …)。Rにデータフレームを読み込む際、各ファイルの文字コードを適切に指定しなければ、コンピュータが文字を読み取れずにエラーが出てしまう。
そのため、Rにcsvファイルを読み込む際は、上記の様にlocale = locale(encoding = "文字コード")で指定する必要がある。また、Webサイトからcsvファイルを保存する時に、文字コードを指定できる場合があるため、その際はUTF-8を選択することをオススメする。3
3.3.2 excelファイルの読み込み:readxl::read_excel()
excelファイルの読み込みは{readxl}パッケージのread_excel()を用いて行なう。ここでは令和5年東京都 国・地域別外国人旅行者行動特性調査のexcelデータを読み込む(本データはここをクリックにある【R5】国・地域別外国人旅行者行動特性調査.xlsxより取得可能)。
# readxlパッケージのインストール・読み込み
install.packages("readxl")
library(readxl)Tokyo_r5 <- read_excel(
# ファイルのパス
"C:/Users/narita yoshiyuki/Desktop/相澤ゼミ_資料/TA/Aizawa_seminar_TA/R_Studio_lec/data/【R5】国・地域別外国人旅行者行動特性調査.xlsx")
# データフレームを軽く表示してみる
Tokyo_r5# A tibble: 11,327 × 227
調査日 国籍 居住地 性別 年齢 入国空港 訪都有無 都内泊数
<dttm> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 2023-02-22 00:00:00 15 6 1 51 2 1 17
2 2023-02-22 00:00:00 3 3 1 39 2 1 4
3 2023-02-22 00:00:00 12 12 1 28 2 1 6
4 2023-02-22 00:00:00 8 8 2 27 2 1 8
5 2023-02-22 00:00:00 18 18 1 42 2 1 13
6 2023-02-22 00:00:00 2 2 1 45 2 1 4
7 2023-02-22 00:00:00 2 2 1 22 2 1 2
8 2023-02-22 00:00:00 12 12 1 23 2 1 3
9 2023-02-22 00:00:00 12 12 1 22 2 1 14
10 2023-02-22 00:00:00 21 21 1 29 2 1 6
# ℹ 11,317 more rows
# ℹ 219 more variables: 訪都回数 <dbl>, 訪都目的 <dbl>, 同行者1 <dbl>,
# 同行者2 <dbl>, 同行者3 <dbl>, 同行者4 <dbl>, 同行者5 <dbl>, 同行者6 <dbl>,
# 宿泊施設1 <dbl>, 宿泊施設2 <dbl>, 宿泊施設3 <dbl>, 宿泊施設4 <dbl>,
# 宿泊施設5 <dbl>, 宿泊施設6 <dbl>, 宿泊施設7 <dbl>, 旅行形態 <dbl>,
# ツアー価格 <dbl>, 航空運賃 <dbl>, マイレージ有無 <dbl>, 支出総額 <dbl>,
# 宿泊費 <dbl>, 飲食費 <dbl>, 都内交通費 <dbl>, 娯楽費 <dbl>, 買物費 <dbl>, …read_csv()と異なり、read_excel()では文字コードを指定する必要がない。先ほどと同様に、画面右上(Environment)の部分にTokyo_r5と表紙されていれば、excelファイルの読み込みも完了である。
4 データフレームの基本的な取り扱い
ここからは読み込んだデータフレームTokyo_r5を用いて、基本的な操作方法を何点か列挙していく。
4.1 R Studioの画面上における操作
ここまで記載されたRコードが上手く実行出来ている場合、R Studioの画面上部(R ScriptとEnvironment)は以下の画像に様になっているはずだ。読み込まれたデータフレームをexcelのように視覚的に確認したい場合、画面の□部分をクリックすれば良い(crimeデータを見たければcrimeの部分を、Tokyo_r5データが見たければTokyo_r5の部分をクリック)。
.jpg)
前述の部分をクリックすると、以下の様に、画面左上のR Scriptがあった部分にデータが視覚的に表示される。あとの補足的な操作は下画面の内容を参照されたい。
.jpg)
4.2 データの抽出
データフレーム内から特定の行・列を抽出する場合データフレーム[行番号, 列番号]を用いる。複数の行・列を抜き出す場合データフレーム[c(行番号1, 行番号2, ...), c(列番号1, 列番号2, ...)]のように、ベクトルと組み合わせれば良い。
# Tokyo_r5のデータの5行目・8列目(都内泊数)を抽出する
Tokyo_r5[5, 8]# A tibble: 1 × 1
都内泊数
<dbl>
1 13# 1,5,7行目・3,5,6列目(居住地, 年齢, 入国空港)を抽出する
Tokyo_r5[c(1, 5, 7), c(3, 5, 6)]# A tibble: 3 × 3
居住地 年齢 入国空港
<dbl> <dbl> <dbl>
1 6 51 2
2 18 42 2
3 2 22 2この操作はデータフレームに関わらず、行列(matrix)やベクトル(vector)のデータ構造においても有効である。
データ分析の際は、どちらかというと特定の列(変数)だけを含めたデータセットが欲しい場合が多い。そのような時は以下の方法が使える。
# [行番号, 列番号]の行番号を指定しない(空白)
Tokyo_r5[ , c("居住地", "都内泊数", "年齢")] # 列番号の部分に変数名を指定してもOK# A tibble: 11,327 × 3
居住地 都内泊数 年齢
<dbl> <dbl> <dbl>
1 6 17 51
2 3 4 39
3 12 6 28
4 8 8 27
5 18 13 42
6 2 4 45
7 2 2 22
8 12 3 23
9 12 14 22
10 21 6 29
# ℹ 11,317 more rows正直なところ、私は上記の方法でデータの抽出を行なっておらず、{dplyr}というパッケージに含まれるselect()やfilter()といった関数を主に用いる。あくまで上記の説明は、基本操作の1つを教えるという教育目的であり、より簡単かつ詳細に行・列の抽出を行なう関数が存在することを明記しておく(それらの関数の説明は coming later !)。4
4.3 変数名の改名
Rでデータ分析をする際に推奨されるのが、変数名を全て半角英数表記にすることである。いちいち半角から変更するのは煩わしく、加えてエラーの原因にもなりやすい全角表記は、Rでの作業において極力避けた方が良いだろう。変数名を変更する時によく用いられるのは、{dplyr}パッケージに含まれるrename()という関数である。
# rename()関数の使い方
dplyr::rename(データフレーム名,
新しい変数名1 = 現在の変数名1,
新しい変数名2 = 現在の変数名2,
...)早速、Tokyo_r5のデータにおける"調査日"と"国籍"の変数名を、"date"と"nationality"に変更してみる。
# dplyrパッケージのインストール・読み込み
install.packages("dplyr")
library(dplyr)# 変数名の変更
rename(Tokyo_r5,
"date" = "調査日",
"nationality" = "国籍")# A tibble: 11,327 × 227
date nationality 居住地 性別 年齢 入国空港 訪都有無 都内泊数
<dttm> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 2023-02-22 00:00:00 15 6 1 51 2 1 17
2 2023-02-22 00:00:00 3 3 1 39 2 1 4
3 2023-02-22 00:00:00 12 12 1 28 2 1 6
4 2023-02-22 00:00:00 8 8 2 27 2 1 8
5 2023-02-22 00:00:00 18 18 1 42 2 1 13
6 2023-02-22 00:00:00 2 2 1 45 2 1 4
7 2023-02-22 00:00:00 2 2 1 22 2 1 2
8 2023-02-22 00:00:00 12 12 1 23 2 1 3
9 2023-02-22 00:00:00 12 12 1 22 2 1 14
10 2023-02-22 00:00:00 21 21 1 29 2 1 6
# ℹ 11,317 more rows
# ℹ 219 more variables: 訪都回数 <dbl>, 訪都目的 <dbl>, 同行者1 <dbl>,
# 同行者2 <dbl>, 同行者3 <dbl>, 同行者4 <dbl>, 同行者5 <dbl>, 同行者6 <dbl>,
# 宿泊施設1 <dbl>, 宿泊施設2 <dbl>, 宿泊施設3 <dbl>, 宿泊施設4 <dbl>,
# 宿泊施設5 <dbl>, 宿泊施設6 <dbl>, 宿泊施設7 <dbl>, 旅行形態 <dbl>,
# ツアー価格 <dbl>, 航空運賃 <dbl>, マイレージ有無 <dbl>, 支出総額 <dbl>,
# 宿泊費 <dbl>, 飲食費 <dbl>, 都内交通費 <dbl>, 娯楽費 <dbl>, 買物費 <dbl>, …調査日、国籍であった2つの変数名が、ちゃんとdate、nationalityに変更されている。
4.4 新たな変数の追加・既存の変数の編集
読み込んだデータフレームに新しい変数(列)を追加したい場合や、既存の変数を編集したい場合が常々ある。その際に利用できる伝統的な方法として、データフレーム名$追加(or編集)する変数名 <- 変数の定義や計算式という書き方がある。データフレーム名$変数名の形は、特定の変数を指定する際に使われる書き方であるため、覚えておいて損はない。
以下では例として、都内泊数の各値からマイナス1した都内泊数2を作成してみる。
# 都内泊数2の作成
Tokyo_r5$都内泊数2 <- Tokyo_r5$都内泊数 - 1
# 都内泊数と都内泊数2を表示してみる
Tokyo_r5[ , c("都内泊数", "都内泊数2")]# A tibble: 11,327 × 2
都内泊数 都内泊数2
<dbl> <dbl>
1 17 16
2 4 3
3 6 5
4 8 7
5 13 12
6 4 3
7 2 1
8 3 2
9 14 13
10 6 5
# ℹ 11,317 more rows先ほど説明した行・列の抽出方法と同様に、変数の追加・編集においても上記の方法より有用なものが存在する。それはdplyr::mutate()という関数であり、複数の変数を同時に追加・編集することが出来る(これもcoming later !)。5
脚注
私の場合、卒業論文では宿泊税と外国人旅行者の宿泊日数の関係性を研究するため、東京都の国・地域別外国人旅行者行動特性調査のデータをWebサイトからダウンロードして分析した。↩︎
他のcsvファイル用の関数として、Rに内蔵されている
read.csv()関数が挙げられる。時間があれば生成AIなどでreadr::read_csv()との違いを調べてみるのもありだろう。↩︎read_csv()はデフォルトの文字コード設定がUTF-8であるため、UTF-8のcsvファイルはlocale = locale(encodeing = "UTF-8")を書かなくて良い。↩︎select(),filter()などといった、行・列の抽出に関するより有益な教材として、私たちのR 13 データハンドリング[抽出]を参照されたい。↩︎mutate()関数の使い方については、私たちのR 15 データハンドリング[拡張]を参照。↩︎